使用Ollama搭建本地的 AI Copilot 编程助手
2024-04-05
前言
最近 Github Copilot 出了点问题,发现身边不少同学如失左膀右臂。之前看到有网友方向通过本地部署 LLM 实现了类似 Copilot 的功能,借此机会我也来尝试自己部署一套看看能否在 Copilot 无法使用期间临时过渡一下。
工具介绍
整套工具链我选择了比较热门的 ollama 部署 deepseek 模型,然后和 IDE 上的 continue.dev 插件进行联动,实现类似 Github Copilot 的代码提示与问答功能。
ollama
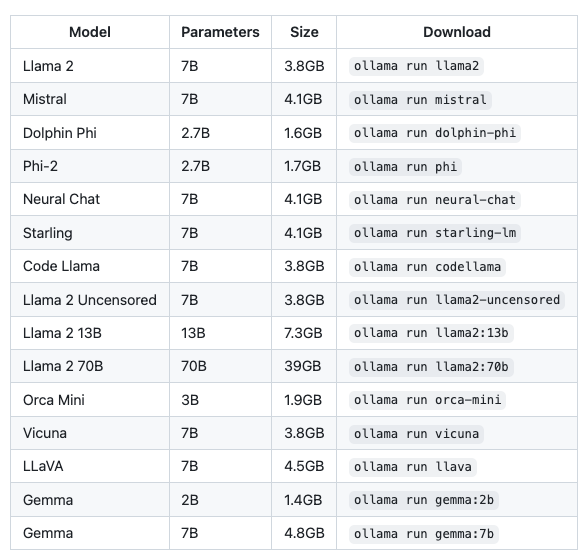
ollama 是一个轻量级、可扩展的框架,专为在本地运行大型语言模型而设计。它简化了模型的设置和配置过程,包括 GPU 的使用,可以很方便地运行并管理常见的开源大模型。在其官网有一个模型仓库可以检索到当前支持的全部模型,基本上主流的开源模型都能找到,一些常用的模型如下:
在这里我主要应用 ollama 来下载安装 deepseek 模型,并提供对应的 HTTP API,如果有同学使用了其他方法的话(如 LM Studio)也是可以的。再提一嘴,ollama 的 api 部分采用了 gin 框架,cli 部分采用了 cobra,是不是后端的同学 DNA 要动了(偷笑)。
deepseek coder 模型
deepseek coder 是知名私募巨头幻方量化旗下的人工智能公司深度求索自主研发的大语言模型,数学和编码能力突出。核心功能是代码自动补全和智能代码建议。它可以理解你的意图,并根据你的上下文提供相关的代码片段。
除了 deepseek 以外,还有 codellama、starcode 等开源模型也可以用作代码生成类的场景,不同模型之间对比参考可以参考 deepseek 放出来的一张图一张图:
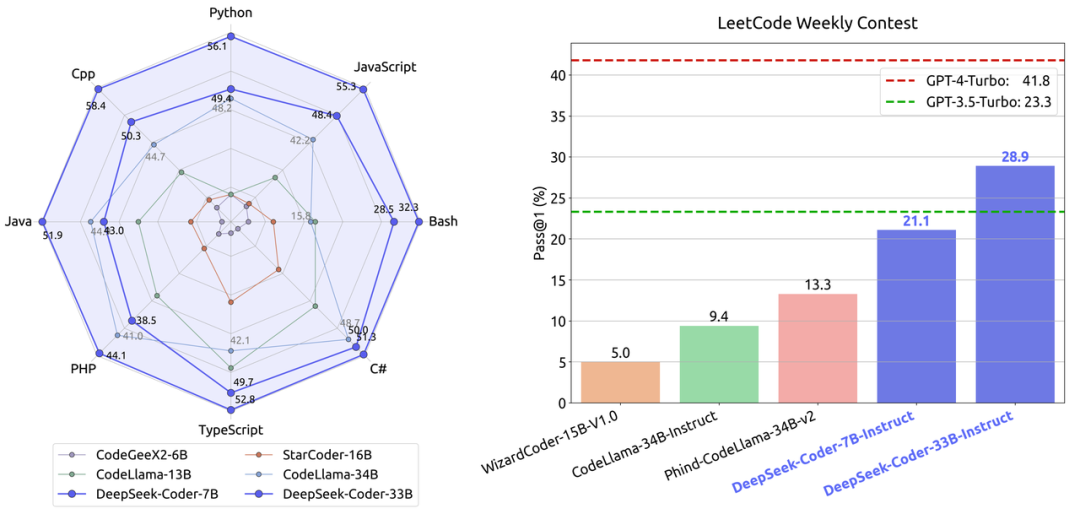
详细的文章可以参考:https://maimai.cn/article/detail?fid=1819575131&efid=LlF0X9Eadl1kryiJ2Qrtcw
continue.dev 插件
continue.dev 是一款开源的 AI 辅助编程插件,支持 VSCode 和 Jetbrains IDE,也支持自定义 API 接口。在这里我便是利用 continue.dev 对接 ollama 的接口,去实现代码的自动完成功能。
我的开发机配置
- MacBook Air M1 2020 版
- 8 核心 Arm CPU, 16G 运行内存
部署过程
- 安装 ollama
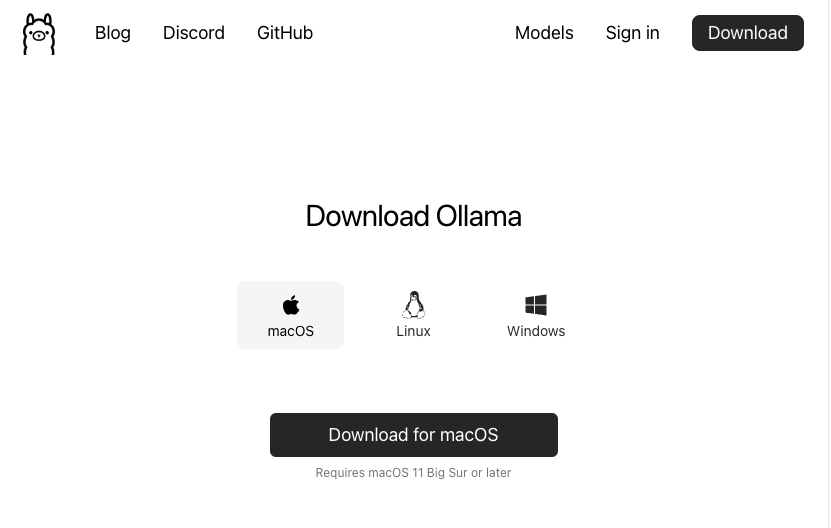
首先进入到 ollama 官网下载页,选择合适的系统版本进行安装
安装完成后可以直接在终端里执行 ollama 看看效果。对于 Mac 系统,安装完成后将会在任务栏展示一个小图标并自动运行 ollama 服务端。如果是 Linux 系统的话需要手动执行一下 ollama serve 启动。
- 下载并运行对应的模型
安装完成之后,只需要简单运行一条命令即可下载 deepseek code 模型。在这里我选择的是 6.7b 的版本
ollama pull deepseek-coder:6.7b我们可以通过下面的命令看到当前已经下载的模型
ollama list也可以直接运行模型进行简单的人机对话的话
ollama run deepseek-coder:6.7b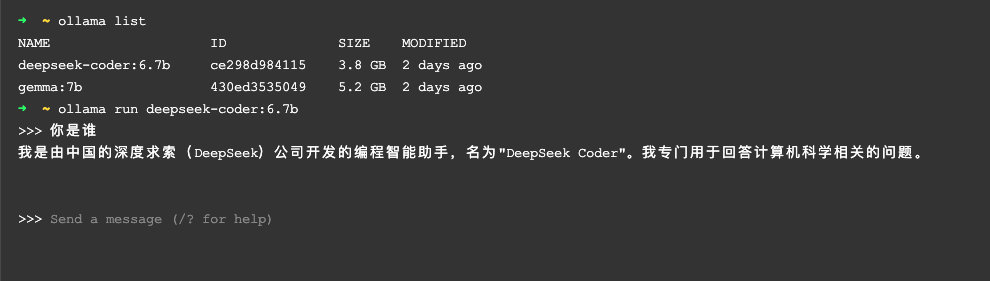
- 安装 continue.dev 插件并配置对应的模型
这里以 VSCode 为例,直接进入到插件市场,搜索 continue 然后安装即可
这个插件大约250M,下载过程比较缓慢,完成安装后需要进行简单的配置。
使用效果
这里简单试了一下自动完成的能力,与 github copilot 的用法基本一致,能够正常为我们生成注释、代码片段以及通过对话的方式生成单元测试。
总结
整个流程跑下来,确实是能够实现类似于 Copilot 的效果,并且可以脱离互联网运行,但是个人认为它的功能还是相对鸡肋。
- 由于是本地部署,个人开发机配置并不算高,因此模型的响应速度不太理想。
- 所选择的模型跑出来的效果不尽人意。由于时间的缘故,我基本上按照网友们的评论跟帖选择了 deepseek 6.7b 的模型,其他同种类的模型如 codellama、starcoder 都没来得及试用,加之开发机无独立显卡、内存空间不大而选择了 6.7b 的版本,“代码提示”的效果远不如 GPT4 模型完善,具体表现为条件判断不严谨、部分代码提示出现非预期错误等等。
- 根据网友使用家用电脑跑大模型的案例,由于电脑没有独立的GPU,使用CPU运算时将会增大内存的带宽负担,有出现内存受损的情况。虽然不排除是个例,但是长时间让开发机处于满载状态会不会影响寿命确实是个值得思考的问题。
时间匆忙,行文催促,并未对各个模型的效果做详细对比,虚心接受各位前辈的指教。